
Our Approach
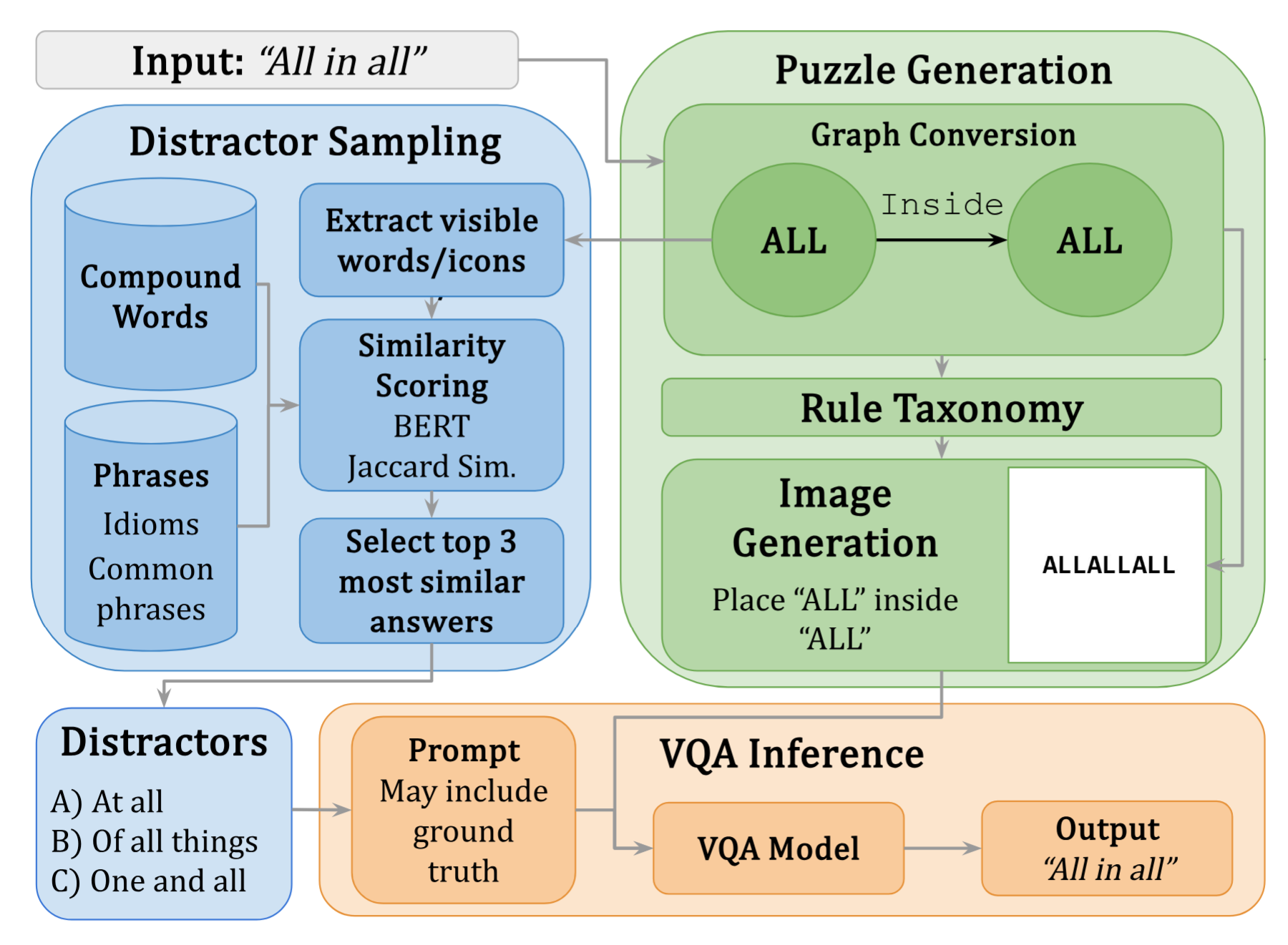
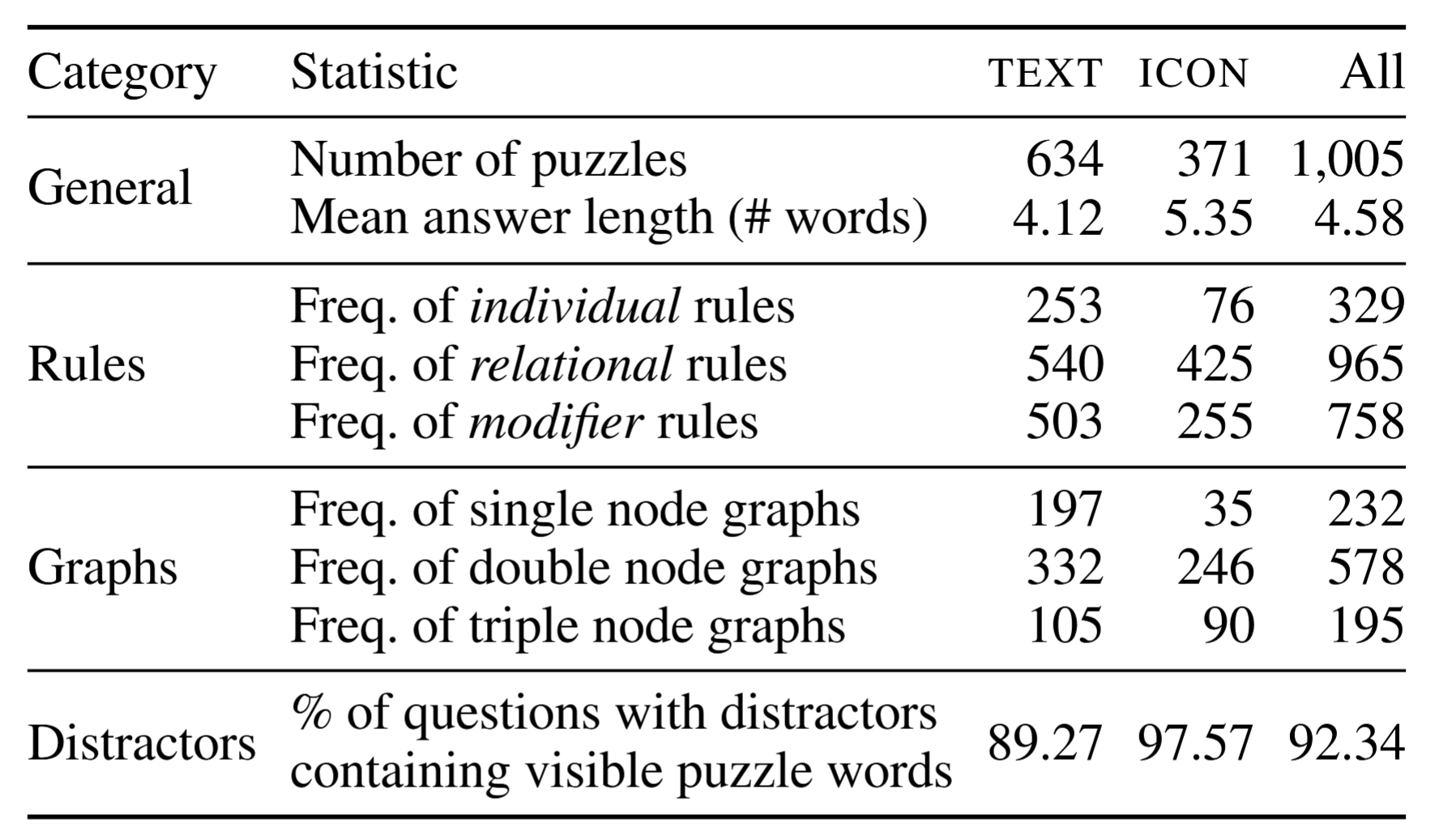
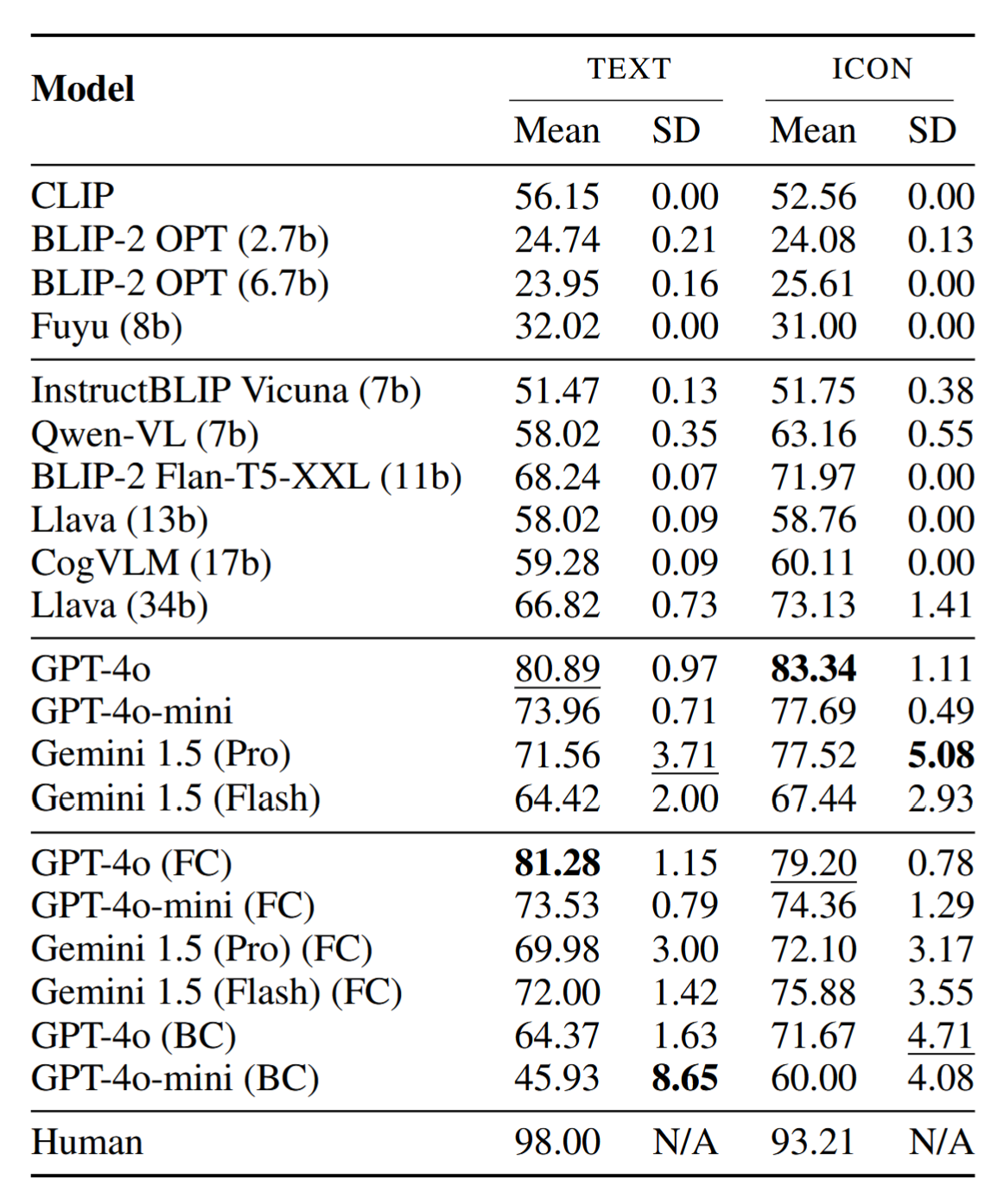
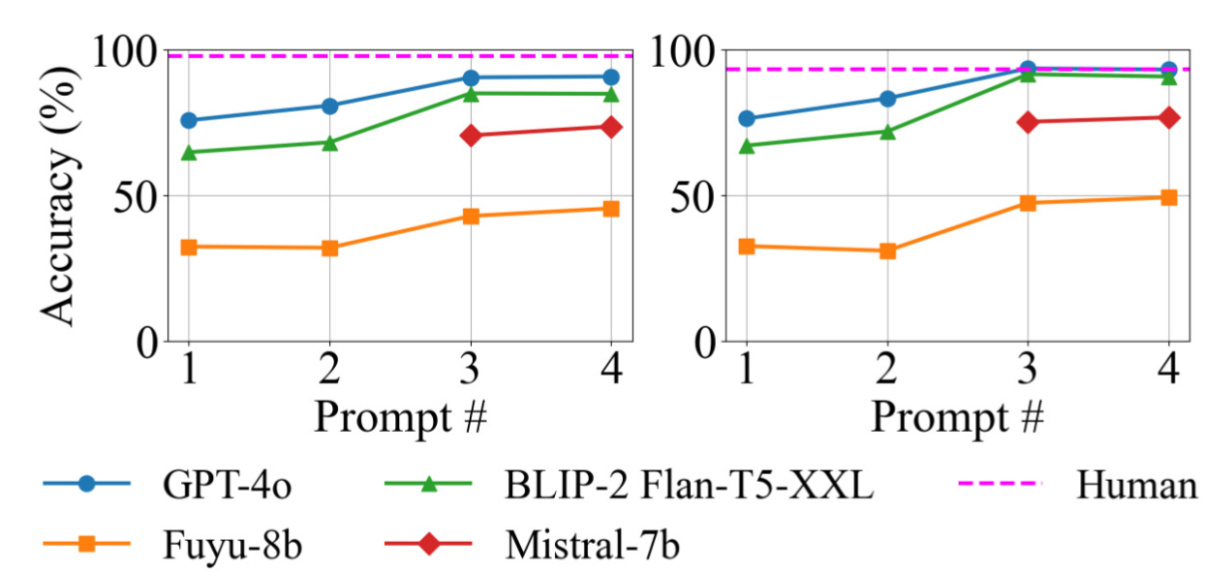
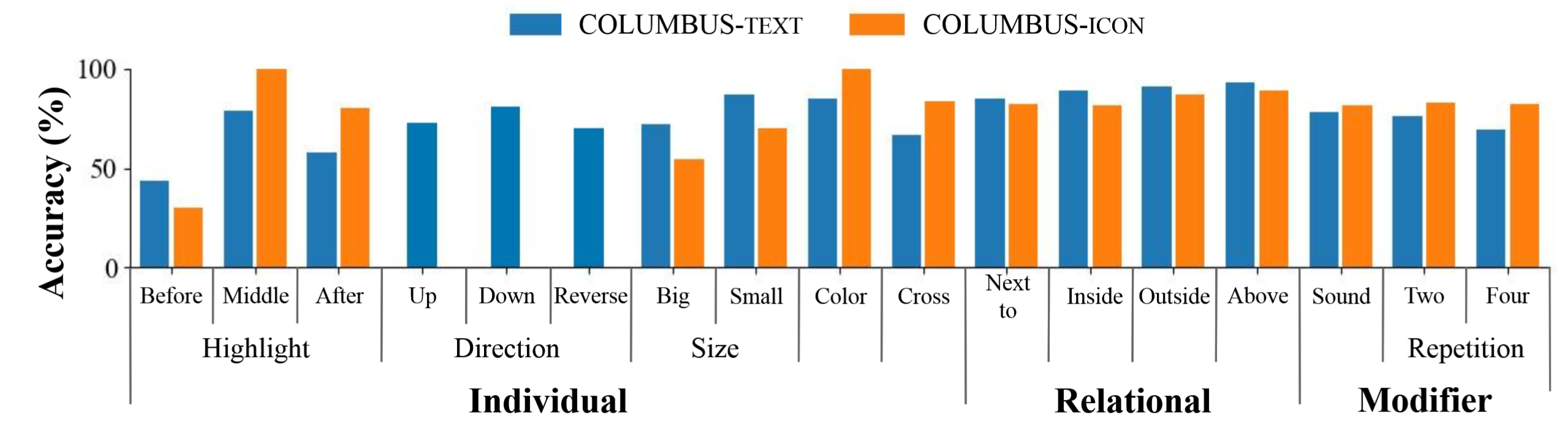
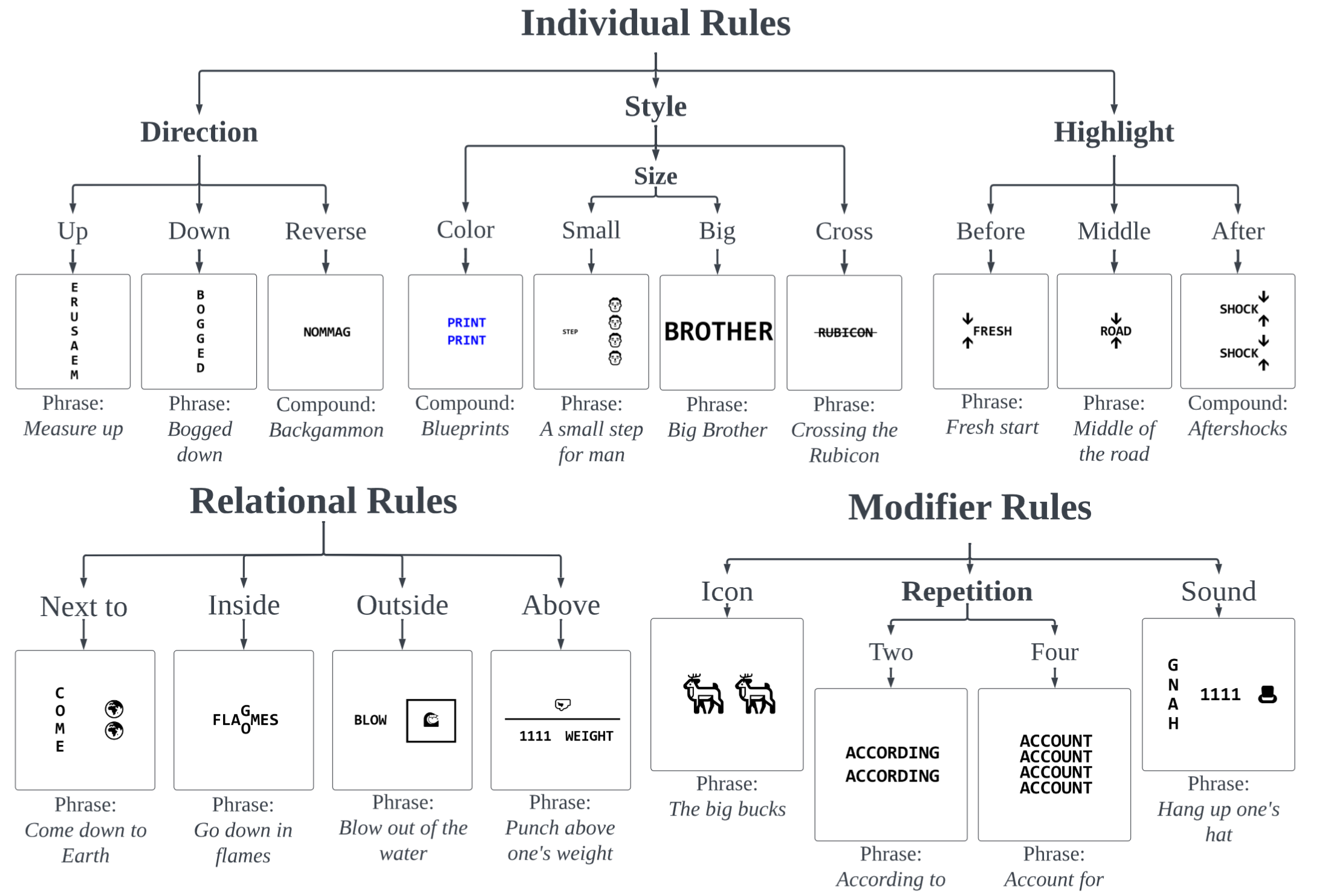
The pipeline to instantiate and evaluate visual lateral thinking tasks is shown below. Puzzle generation leverages the above taxonomy to create a graph representation for a puzzle answer and generate an image for the graph. Each graph is a directed, attributed graph whose nodes are elements that will be rendered into a puzzle image. The node attributes specify the rendering of that element (i.e., the individual or modifier rules that will apply to it). The edges between two nodes are annotated with an attribute that specifies their relational rule. The distractor sampling step is based on a weighted average of orthographic and semantic similarity between a puzzle’s correct answer and its visible elements.